One of my favorite parts of teaching the System Design Bootcamp is the live engagement and Q&A. The questions often reveal common gaps in understanding that aren't obvious until someone says them out loud.
In a recent session, we were discussing scaling strategies. I explained that to scale complex search queries, you should offload that data to a specialized Inverted Index (like Elasticsearch). Later, I mentioned that if a database is overwhelmed by read traffic, you can improve performance by adding a Cache.
A participant raised their hand and asked a great clarifying question:
This revealed a subtle but critical misunderstanding. The participant viewed these as mutually exclusive options: "Option A vs. Option B." In reality, they are two different dimensions of system design.
I wanted to share the clarification here, as it is a foundational concept for anyone designing scalable systems.
1. The "Storage Engine": Chosen by Data Structure & Query Pattern
The first decision you make is where the data lives permanently (the "System of Record"). You choose this technology based on the structure of the data and the complexity of the queries you need to run.
- Transactional data (ACID): If you need strict consistency for banking or orders, you choose a Relational Database (PostgreSQL, MySQL).
- Key-value / flexible data: If you have massive scale and simple access patterns, you might choose a NoSQL store (DynamoDB, Cassandra).
- Complex text search: If you need to search for "fuzzy" matches or relevance (e.g., "iPhone cases red"), a standard database is too slow. You choose an Inverted Index (Elasticsearch, Solr).
- Large blobs: If you are storing images or videos, you choose Blob Storage (AWS S3).
Fundamentally, the storage engine is defined by the nature of your data.
2. The "Caching Layer": Chosen by Access Frequency
The second decision is how to optimize access. You introduce caching when you need to save round-trips to the original source or reduce latency for "hot" data.
Note that caching can sit in front of any of the storage engines mentioned above.
- Cache + database: You use in-memory caching (such as Redis) to store the result of complex queries. If a "Product Details" page requires joining five tables, you compute it once and store it temporarily in memory, avoiding the slow database trip for every user.
- Cache + blob storage: You use a Content Delivery Network (CDN) to overcome lags caused by geographical distance. Your S3 bucket may live in a single data center (e.g., "US-East"). Without a CDN, a user in Tokyo has to fetch data all the way from the US. A CDN caches copies of your images on "edge" servers around the world, so the user fetches from a local server in Tokyo instead.
- Cache + search engine: This is the part that often surprises people. Yes, Elasticsearch is fast. But if 10,000 users are searching for "World Cup" every second, you shouldn't hit the search engine 10,000 times. You can cache that popular search result in Redis or a CDN.
The Layered Architecture
In a mature system, you often layer these technologies.
Imagine an e-commerce site. When a user searches for a product, the flow might look like this:
- The cache check: Your service checks Redis. "Do we already have the search results for 'red shoes'?"
- The search engine: If the cache is empty, the service queries Elasticsearch (the specialized storage).
- The data retrieval: Elasticsearch returns the IDs of the products. The app might then fetch the full product details from PostgreSQL (the transactional storage) or DynamoDB and save them in the Redis cache for future reference.
- The asset load: The product images are loaded from a CDN (which caches the files stored in S3).
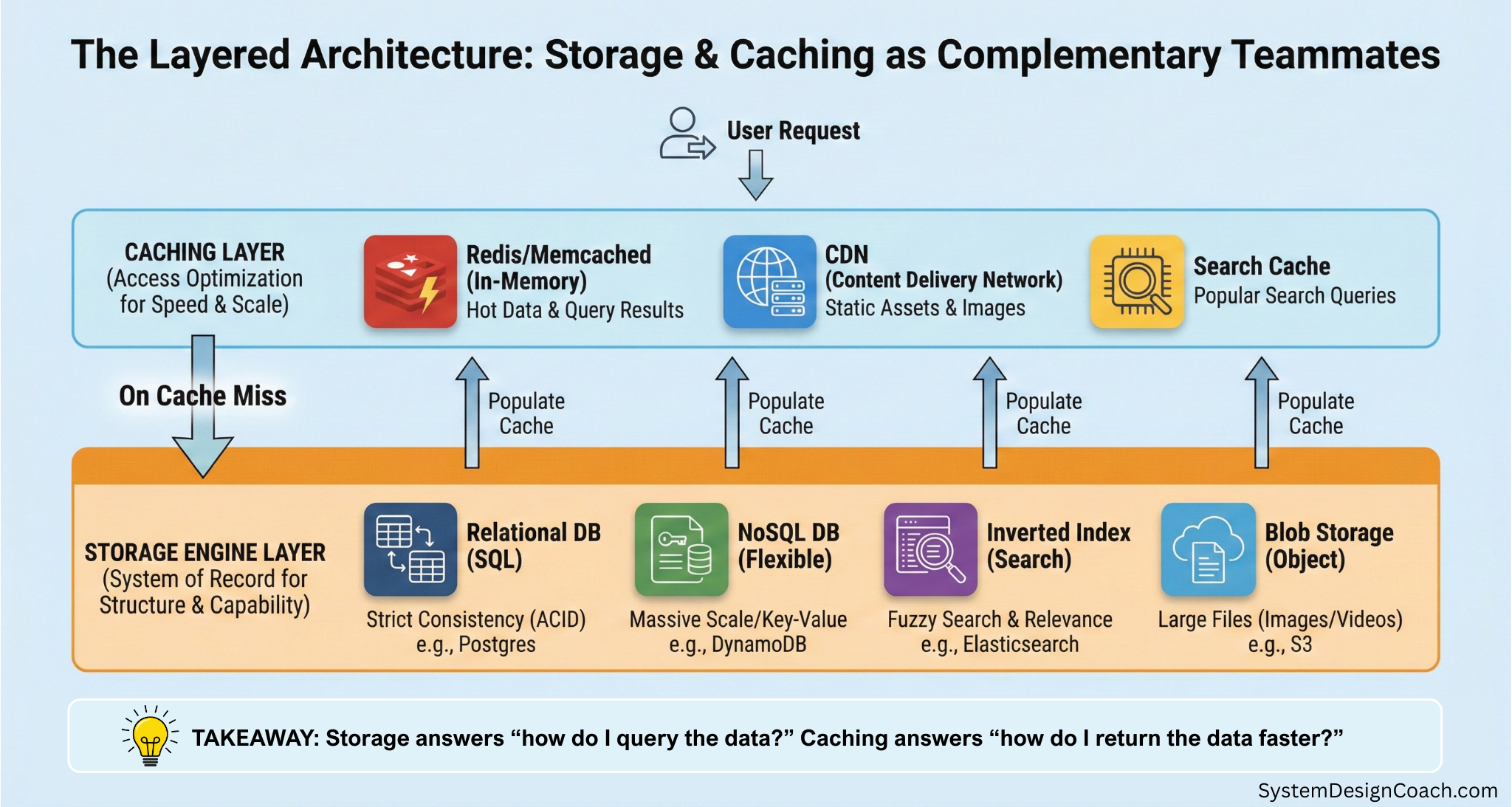
Summary
When designing a system, separate your concerns:
- Ask: "What are the data structure and the query pattern?" This dictates the Storage Engine you need (SQL, NoSQL, Elasticsearch, or blob storage).
- Ask: "What is the access frequency?" This tells you where you need Caching (Redis, CDN, etc.).
They are not mutually exclusive; they are essential partners in scale.