Decoupling your search index from your primary database is the standard move for scalability, but it introduces a complex distributed systems challenge: Data Drift.
At scale, keeping a search index consistent with a primary database breaks down into the following key pillars.
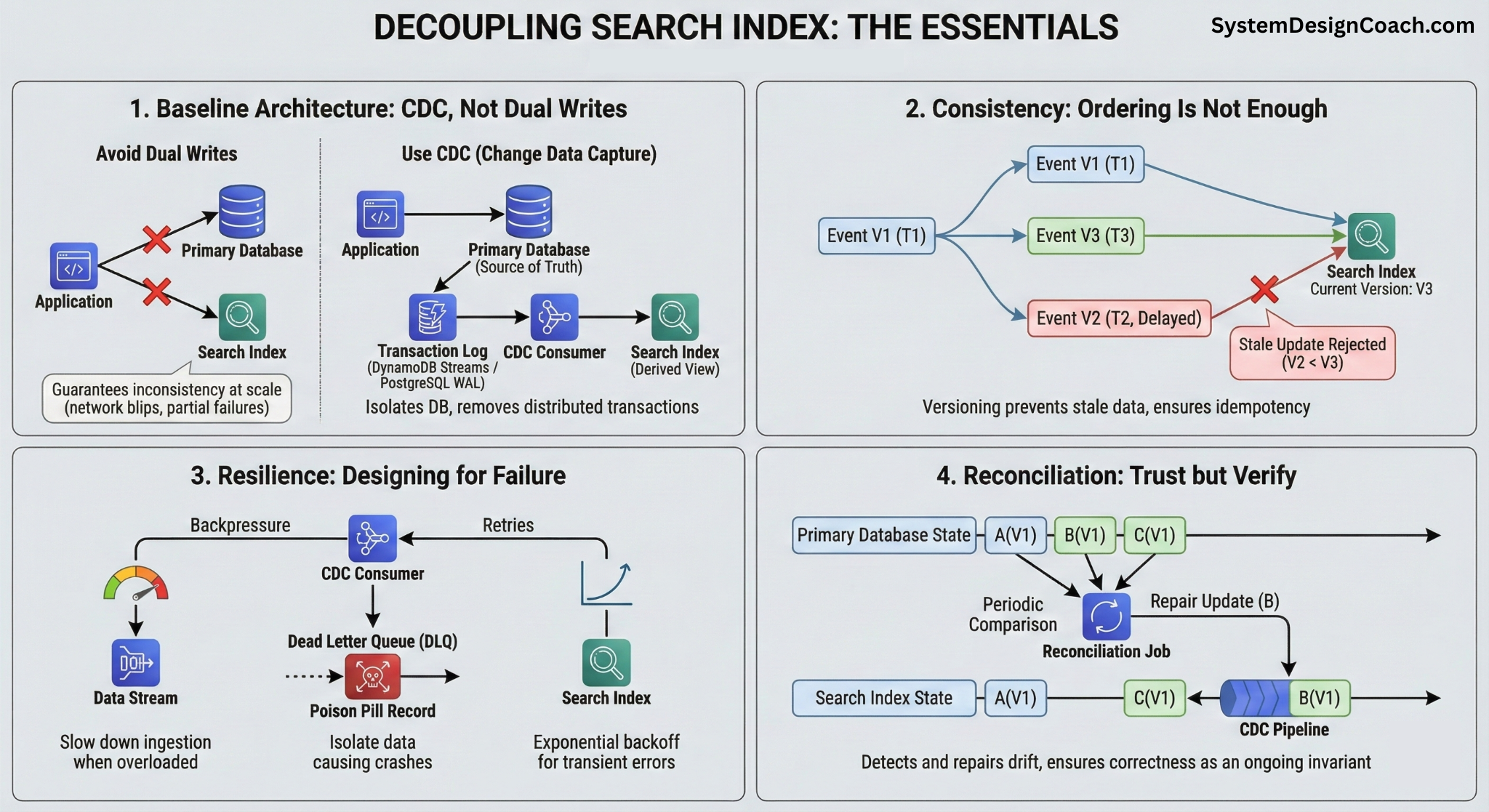
1. Baseline Architecture: CDC, Not Dual Writes
The primary database must remain the single source of truth.
Updating the database and search index in the same request (dual writes) guarantees inconsistency at scale. Network blips or partial failures will eventually leave one system updated and the other stale.
The solution is to use Change Data Capture (CDC):
- All writes go only to the database.
- Stream changes asynchronously from the database transaction log (DynamoDB Streams or PostgreSQL WAL) to downstream consumers.
- Treat the search index as a derived view, strictly following the database's state.
This decoupling isolates the database from downstream failures and removes complex distributed transactions from your write path.
2. Consistency: Ordering Is Not Enough
CDC pipelines are not always perfectly ordered or lossless.
Events can arrive late, arrive twice, or be replayed out of sequence during recovery. A naive consumer that blindly applies every update will eventually overwrite new data with old data.
The solution is to use versioning:
- Each change event includes a version from the source (e.g. timestamp, sequence number).
- The search index applies an update only if its version is newer than what is already stored.
- This prevents stale updates from overwriting newer state and makes the pipeline idempotent by design.
3. Resilience: Designing for Failure, Not just the Happy Path
Components will fail; the pipeline must not stop.
In production, consumers of data streams may crash, search clusters may throttle, and bad data may break parsers. If your pipeline isn't resilient, a single error can block millions of updates.
The solution is to build isolation and backpressure:
- Backpressure: Consumers must slow down ingestion when the search index is overloaded, rather than crashing.
- Dead Letter Queues (DLQ): "Poison pill" records (data that causes crashes) must be isolated to a side queue so the main stream keeps moving.
- Retries: Implement exponential backoff for transient network errors.
4. Reconciliation: Trust but Verify
CDC guarantees delivery, not correctness.
Even the best pipelines drift. Retention windows expire, bugs silently drop events, and human operators make mistakes. If you rely solely on the stream, your index will slowly diverge from reality.
The solution is to run a periodic reconciliation job:
- Periodically compare database state with index state
- Detect missing or stale documents
- Repair discrepancies by re-emitting updates through the same CDC pipeline
This turns correctness from a one-time setup into an ongoing invariant.
Initial backfills and managed CDC services introduce additional considerations. For more details on these topics and comprehensive implementation guidance, see the full deep-dive article here.