In this article, I explained how an inverted index works. Let's now talk about where that index should live.
A common misconception I often see in System Design interviews is:"We can keep search in the main database for now. Moving search to a separate service is a nice-to-have."
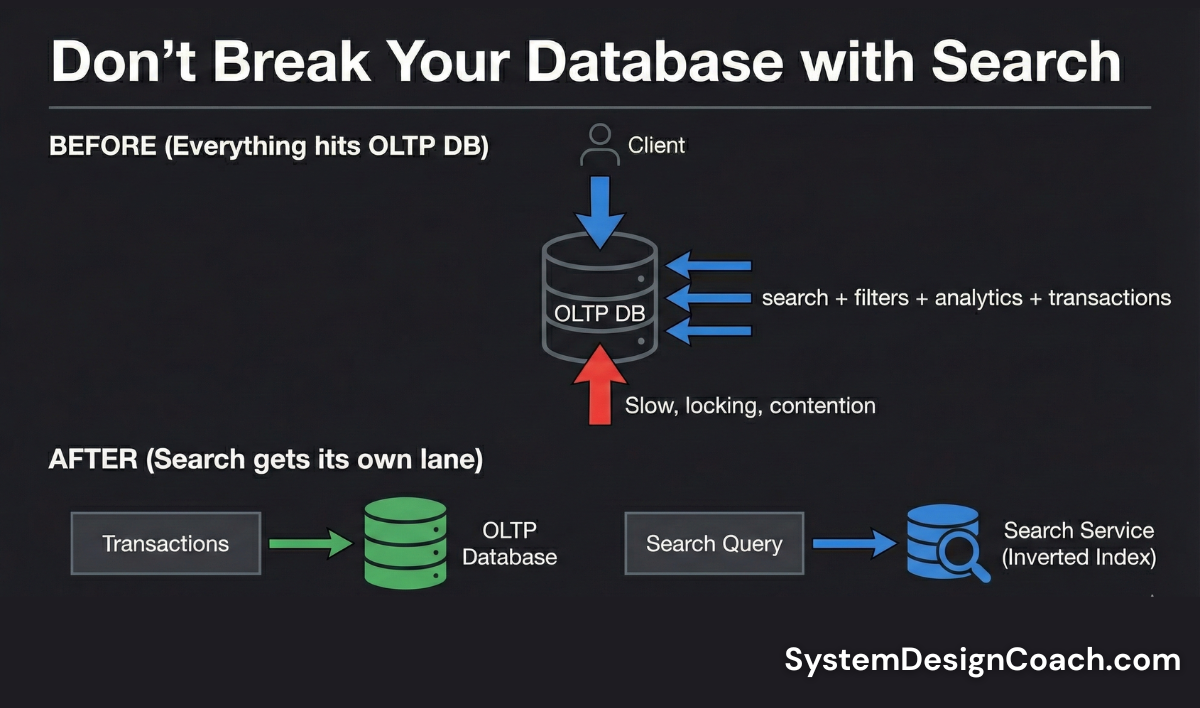
If search is central to your product, moving it out is not a "nice to have." It is a must-have.
Large, unbounded search queries are one of the fastest ways to overwhelm an OLTP (transactional) database.
A Real Example from Amazon
In my early days at Amazon, I led the case management platform that automatically created a case whenever a seller contacted Amazon Support.
- The Setup: Our backend ran on a relational database. It handled core transactions effortlessly.
- The Problem: Support associates started running heavy search queries to find cases using keywords and complex filters in real-time.
- The Result: Massive performance degradation. Complex search queries locked up resources and slowed down core transactional workloads for everyone else.
The Solution
We moved search out of transactional database and into a dedicated service backed by its own inverted index.
✅ Database contention disappeared
✅ Search became dramatically faster
✅ Our OLTP system finally behaved like an OLTP system again
This pattern holds true across nearly every system at scale.
The Takeaway
If search is a first-class citizen in your product, give it its own index, its own service, and its own infrastructure.
Your primary database, your on-calls, and your customers will thank you.
Next: Once you've separated search into its own service, you need to keep it in sync with your database. Learn the essentials of decoupling your search index.